
CRUD : 데이터를 다루는 가장 기본적인 동작
1. CREATE
데이터베이스를 만들고 사용하기 (CREATE, USE)
- a1이라는 데이터베이스가 있으면 삭제
- a1이라는 데이터베이스를 생성
- a1을 사용
DROP DATABASE IF EXISTS a1
CREATE DATABASE a1
USE a1;
데이터베이스의 목록과 테이블의 목록을 보기 (SHOW)
- DESC : 테이블의 구조 확인
SHOW DATABASES;
SHOW TABLES;
DESC 테이블명;
dept(부서명) 테이블을 생성하기 (CREATE)
- id에 기본 키를 부여하고 숫자가 자동으로 증가함
- 모든 컬럼은 NULL을 허용하지 않음
- name 컬럼은 중복을 허용하지 않음
CREATE TABLE dept(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY(id),
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL UNIQUE
);
dept 테이블에 데이터를 삽입함 (INSERT INTO)
- reDate의 시간을 NOW()로 설정
- NOW() : 현재 시간을 불러오는 함수
INSERT INTO dept
SET regDate = NOW(), `name` = '홍보';
INSERT INTO dept
SET regDate = NOW(), `name` = '기획';
emp 테이블을 생성하기 (CREATE)
CREATE TABLE emp(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY(id),
regDate DATETIME NOT NULL,
`name` CHAR(100) NOT NULL,
deptid INT UNSIGNED NOT NULL,
salary INT UNSIGNED NOT NULL
);
emp(사원정보) 테이블에 데이터를 삽입함 (INSERT INTO)
- regDate(입사일), name(사원이름), deptid(부서번호), salary(연봉)
INSERT INTO emp
SET regDate = NOW(), `name` = '홍길동', deptid = 1, salary = 5000;
INSERT INTO emp
SET regDate = NOW(), `name` = '홍길순', deptid = 1, salary = 6000;
INSERT INTO emp
SET regDate = NOW(), `name` = '임꺽정', deptid = 2, salary = 4000;
2. READ
SELECT 문의 논리적 수행 순서
SELECT ----- 5️⃣
FROM ------ 1️⃣
WHERE ------ 2️⃣
GROUP BY --- 3️⃣
HAVING ------ 4️⃣
ORDER BY ---- 6️⃣
부서별로 부서명, 사원리스트, 평균-최고-최소 연봉, 사원 수 조회하기
#v1 조인 사용하지 않고 조회
- IF문 사용
SELECT IF(deptId = 1, '홍보', '기획') AS `부서명`,
GROUP_CONCAT(`name` ORDER BY id DESC SEPARATOR ', ') AS `사원리스트`,
CONCAT(TRUNCATE(AVG(salary), 0), '만원') AS `평균연봉`,
CONCAT(MAX(salary), '만원') AS `최고연봉`,
CONCAT(MIN(salary), '만원') AS `최소연봉`,
CONCAT(COUNT(*), '명') AS `사원수`
FROM emp
GROUP BY deptid;- CASE문 사용 + 중복 제거
SELECT CASE
WHEN deptid = 1 THEN '홍보'
WHEN deptid = 2 THEN '기획'
ELSE '무소속' END AS `부서명`,
GROUP_CONCAT(`name` ORDER BY id DESC SEPARATOR ', ') AS `사원 리스트`,
TRUNCATE(AVG(salary), 0) AS `평균연봉`, MAX(salary) AS `최고연봉`, MIN(salary) AS `최소연봉`,
COUNT(*) AS `사원 수`
FROM emp
GROUP BY deptid;
#v2 조인해서 부서명까지 조회
SELECT D.name AS `부서`,
GROUP_CONCAT(E.name) AS `사원리스트`,
TRUNCATE(AVG(E.salary), 0) AS `평균연봉`, MAX(E.salary) AS `최고연봉`, MIN(E.salary) AS `최소연봉`,
COUNT(*) AS `사원수`
FROM emp AS E INNER JOIN dept AS D ON E.deptid = D.id
GROUP BY E.deptid;
#v3 HAVING절 사용하여 평균연봉이 5000 이상인 부서로 추려서 조회
SELECT D.name AS `부서`,
GROUP_CONCAT(E.name) AS `사원리스트`,
TRUNCATE(AVG(E.salary), 0) AS `평균연봉`, MAX(E.salary) AS `최고연봉`, MIN(E.salary) AS `최소연봉`,
COUNT(*) AS 사원수
FROM emp AS E INNER JOIN dept AS D ON E.deptid = D.id
GROUP BY E.deptid
HAVING `평균연봉` >= 5000;
#v4 HAVING절 대신 서브쿼리를 수행하여 조회
SELECT *
FROM (
SELECT D.name AS `부서명`,
GROUP_CONCAT(E.`name`) AS `사원리스트`,
TRUNCATE(AVG(E.salary), 0) AS `평균연봉`, MAX(E.salary) AS `최고연봉`, MIN(E.salary) AS `최소연봉`,
COUNT(*) AS `사원수`
FROM emp AS E INNER JOIN dept AS D ON E.deptid = D.id
WHERE 1
GROUP BY E.deptId
) AS D
WHERE D.`평균연봉` >= 5000;3. UPDATE
기존 컬럼의 값을 수정하기
emp 테이블에서 '홍길동'이라는 이름을 가진 데이터의 연봉을 6000으로 수정
UPDATE emp
SET salary = 6000
WHERE `name` = '홍길동';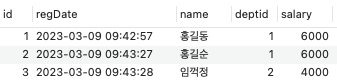
4. DELETE
특정 컬럼 값을 삭제하기
emp 테이블에서 '홍길동'이라는 이름을 가진 데이터를 삭제
DELETE FROM emp
WHERE `name` = '홍길동';